Using Unisound Realization Android Voice Broadcast
It is relatively easy to implement voice broadcast on Android. The first reaction is to use the TTS that comes with the system. However, the support for Chinese is not good. Secondly, it is inconvenient to customize the voice effect. Third-party voice broadcast solutions are a natural choice.
There are many third-party voice broadcast programs, such as Xunfei, Baidu, and Unisound. This article uses offline broadcast programs. Xunfei’s offline charges are not low. Baidu is the default network, so only Unisound is optional.
Unisound’s vision into the public should be at the launch of the Smartisan. Like every open platform, you must first register as a developer.
Preliminary Preparation
- Register as a Unisound developer
Go to Unisound Open platform, Fill in the registration information to become a developer.
- Add new app
Click My Apps and select “Add New Application”. We want to use offline voice synthesis, so choose the general solution and fill in the introduction information. Complete the app registration.
- Check APPKEY and SECRET
Click on the newly created application, you can see the APPKEY and SECRET corresponding to the application.
- Download the Development Kit
Go to the SDK Download Page, select “Universal Solution - Android - Offline Speech Synthesis”, and then download the SDK.
- Configuration project structure
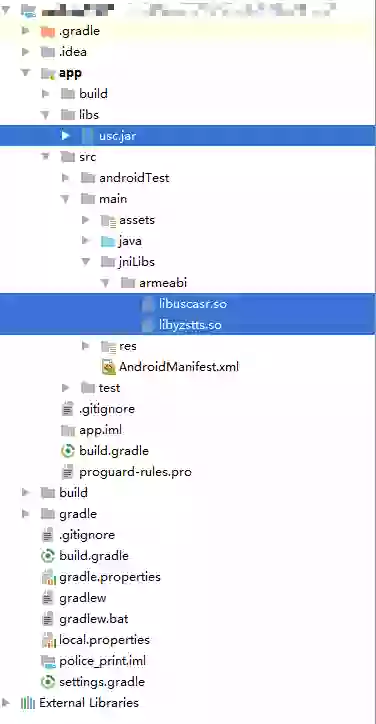
Find the Demo and the documentation from the downloaded SDK development package. It should be noted that the Demo is a project built with Eclipse, so the project structure is slightly different, and it can be configured according to the following figure. usc.jar is placed in the libs directory under the app, and the two so files are placed in jniLibs under main.
Application Development
To use the offline voice service, you also need a voice model. This project below puts the voice model in the assets and then copies the code to the SD card. Each project can handle the model storage location according to the scene requirements.
- First new a file named
TTSUtils.java, as follows
1 |
|
- Initialize at the appropriate location
Initialize in Application.class or specific Activity
1 | TTSUtils.getsInstance().initTts(this); |
Then use the following code to play.
1 | TTSUtils.getsInstance().getmTTSPlayer().playText("Put your text here to play(Include Chinese)"); |
Attention
- You need to add jar related in the
build.gradledependencies
1 | implementation files('libs/usc.jar') |
- If the voice model is placed in the assets, it takes time (about 1 second) to copy from the assets to the sd card. If there is no model when the cloud is initialized, an empty exception will be thrown when the playback function is called.
- There are fewer offline voice models, and more models can be contacted for business purchases or online.
- The development documentation is old and there is no technical support. It is recommended to understand the function through the Demo code.