Build a crawler agent pool
Anti-reptiles are numerous, the most common one is to check the Header, and the second is to block the IP based on the frequency of the visit. There are many websites that provide agents on the Internet, but the actual available IP is very small, and the purchase of the charging interface is not suitable for small projects. Therefore, it is very necessary to build a pool of your own crawler agent.
Effect
The schematic diagram of the program operation is as follows: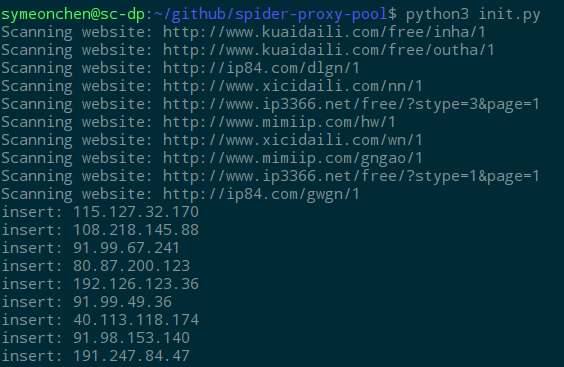
The database diagram is as follows: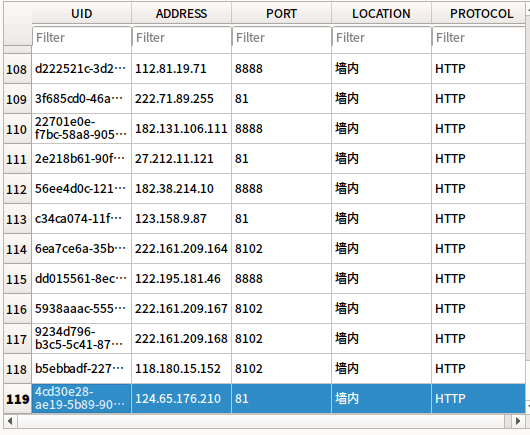
Introduce
To get the available proxy IP, the port scan efficiency is too low. Considering the daily demand of the crawler is not large, it is most convenient to climb down from the existing proxy website. During the actual testing process, it was found that the IP availability rate provided by online proxy websites is also very low. It may be that their detection rules use Baidu and other websites as targets to check the return value. However, this method is not accurate. After all, many agents may be reversed. Well-known sites such as Baidu.
Due to the different processing methods of X_FORWARDED_FOR, the classification of agents on the network is divided into transparent proxy and anonymous proxy, and anonymous proxy is divided into general agent and high-hiding agent. Since it is for the hidden nature of reptiles, you can only consider the high-hiding agent and do it yourself.
Step
First look for some existing agency websites, Google can find a lot. Analysis of their characteristics, found that IP, port, protocol are displayed in a table, naturally think of using BeautifulSoup’s find_all to filter, plus IP and other data format determination, you can unify the screening rules of all sites, write a general crawler It is.
After climbing the data, you need to save it into the database, using sqlite3, in fact, still use the SQL syntax, so it is best to package it.
The next step is to verify the availability of the IP. Here, http://httpbin.org/ip is used as the basis for judging. If the returned url is the same as the proxy, then the IP is determined to be available.
After determining that the IP is available, call the Taobao interface to get the geographical location of the IP and update it to the database.
The full code is on my Github[(https://github.com/SymeonChen/spider-proxy-pool)] (https://github.com/SymeonChen/spider-proxy-pool). Here are some key codes posted.
It is I/O intensive to determine whether IP is available, so multithreading is faster, so multiprocessing.dummy is called here.1
2
3
4
5
6
7
8from multiprocessing.dummy import Pool as ThreadPool
pool = ThreadPool(30)
results = dboperation.selectAllAddress()
pool.map(ipverify.checkAllAddress,results)
pool.close()
pool.join()
To determine whether the IP format is correct, there are many online methods, here the ipaddress module is called to complete the check, so the Python version must be greater than 3.3.1
2
3
4
5
6
7
8import ipaddress
def ip_isvalid(address):
try:
ipaddress.IPv4Address(address)
return True
except ipaddress.AddressValueError:
return False
Problem
- The proxy availability is low. If you need more than 100+ agents, you need to increase the crawled website.
- No external service is provided. Although the available IP is available, it is more convenient to call if it is made into an API.